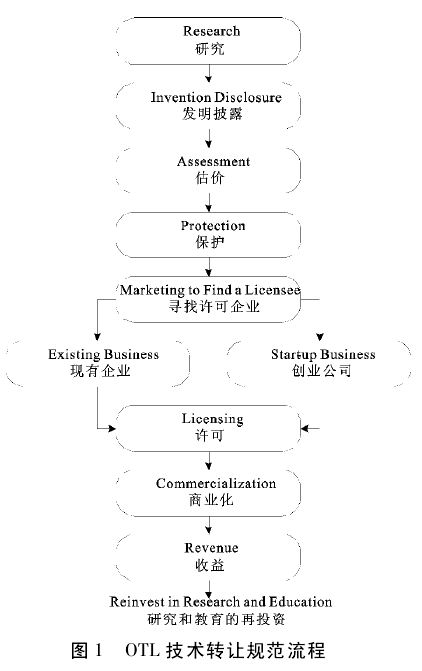
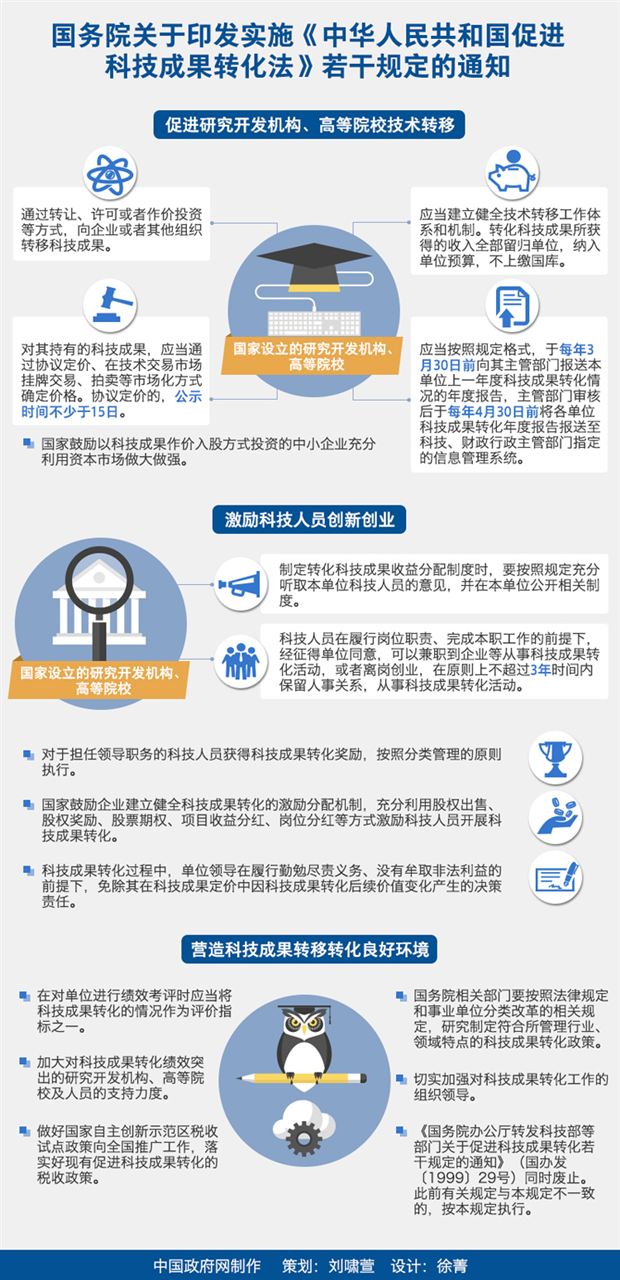
在科技日新月異的今天,技術成果轉讓及其相關技術服務已成為推動產業升級、促進創新轉化的關鍵環節。一份規范的《技術成果轉讓合同》不僅明確了雙方的權利義務,更是保障技術交易安全、實現技術價值最大化的重要法律工具。本文將圍繞技術成果轉讓與技術服務的核心內容,探討合同的關鍵要素及實踐中的注意事項。
一、技術成果轉讓合同的核心要素
技術成果轉讓合同的核心在于明確轉讓標的、權利義務及對價。合同需清晰界定轉讓的技術成果,包括專利、專有技術、軟件著作權等,并附詳細的技術資料清單。轉讓方式(獨占、排他或普通許可)及地域、期限限制需明確約定。價款支付方式通常采用分期支付,與技術資料的交付、培訓服務的完成等里程碑掛鉤。技術成果的權利保證條款至關重要,轉讓人應保證其對技術成果擁有完整、無瑕疵的知識產權,不存在侵犯第三方權利的情形。
二、技術服務條款的協同作用
技術服務往往是技術成果轉讓不可或缺的配套內容。技術服務條款應包括服務范圍、標準、時間、地點及人員安排等具體內容。例如,技術培訓、設備調試、后續升級支持等服務,都需明確服務標準和驗收條件。服務費用的計算方式(固定總價、按工時或按效果付費)及支付節奏也需詳細約定。特別要注意的是,技術服務過程中產生的新的知識產權歸屬問題,應在合同中預先明確,避免日后糾紛。
三、保密與違約責任條款
鑒于技術成果的敏感性,保密條款是合同的基石。合同應定義保密信息的范圍,設定保密期限(即使合同終止仍應持續),并明確違約責任。違約條款應全面覆蓋各種違約情形,如延遲交付技術資料、技術不達標、泄密等,并規定相應的違約金、賠償金計算方式及合同解除權。合理的違約責任設定能有效約束雙方行為,保障合同順利履行。
四、實踐中的常見風險與應對
在實踐中,技術成果轉讓常伴隨風險。例如,技術價值評估不準確、技術更新迭代導致成果貶值、或技術實施依賴特定團隊等。為應對這些風險,建議在合同中加入技術擔保條款,要求轉讓人保證技術成果符合約定的技術指標,并可在一定期限內提供必要的技術支持。可設置價格調整機制,如按技術實施后的經濟效益分期支付尾款。爭議解決條款應明確選擇仲裁或訴訟方式,并約定管轄機構,以便高效解決糾紛。
五、結論
一份周全的《技術成果轉讓合同》應深度融合技術成果轉讓與技術服務條款,兼顧法律嚴謹性與商業靈活性。雙方在簽約前應充分溝通,明確技術細節與商業預期,借助專業法律人士完善合同文本。唯有如此,才能確保技術成果順利轉化,實現雙贏,為科技創新與產業發展注入持續動力。